[Python] Virustotal api using python
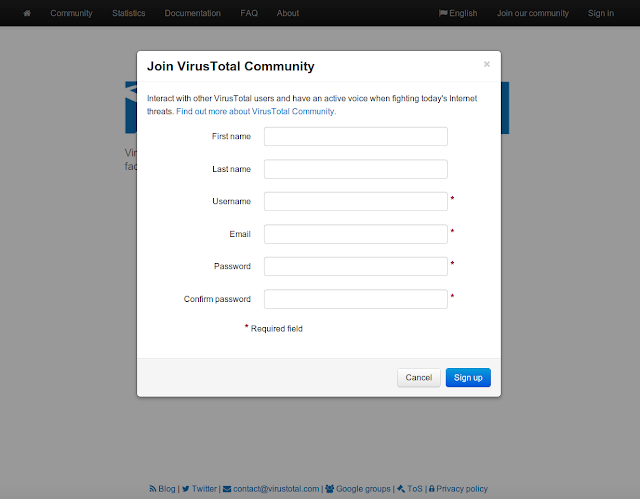
雖然本身接觸到不少病毒資料, 不過每次都靠上傳檔案到 Virustotal 實在非常的沒效率 寫程式用 url upload 也不是不行, 不過其實他是有釋出 API 可以用的 一般帳號的 API 規定 1 分鐘最多 4 個 request, 而且是透過 http post 的方法且回傳是 json 格式 ( The chosen format for the API is HTTP POST requests with JSON object responses and it is limited to at most 4 requests of any nature in any given 1 minute time frame ) 這篇參考的是他的 API 教學頁面, 做一個簡易的上傳跟擷取講解 (目前時間大約是 2013/12/23) Official Source: https://www.virustotal.com/en/documentation/public-api/ 而使用他的 API 需要 API key, 這需要先註冊帳號才可以 首先, 英文版右上方有一個 Join our community (中文是加入我們社群) 依序填完相關資料即可, 這邊應該是沒什麼太大的難度 但是注意信箱要填正確, 他會寄確認通知, 等點了確認通知信之後才會正式開啟 之後到 virustotal 登入, 點右上角的帳號選擇 profile, 就會出現一些相關訊息, 點API就會看到API KEY 中間那個 API KEY複製下來之後, 就可以開始使用了 (他下面的聲明是說如果你用不夠想要更多的數量需求, 再寫信跟他要) 以下都是使用 python code 為範例 Upload Suspicious File 官網是建議利用 httplib 來跟 virustotal 提供的 api 做溝通, 但有三件事情要修改跟注意 首先會看到官網有提供一段 code import postfile host = "www.virustotal.com" selector = "https://www.virustotal.com/vtapi/v2/file/s