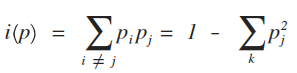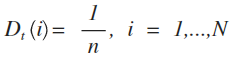kNN - K Nearest Neighbor 這個演算法是滿單純簡單的, 所以簡單提一下原理就好 首先, 大部分的 ML 狀況大致上都如下 假設我手上有一筆資料, 有很多的特徵跟每筆資料的類別都有 然後有人給我一筆只有特徵但不知道類別的資料, 我要怎麼辨識他 那, 單純一點的問題, 假設今天你要透過收集人臉, 來辨識人種 所以你可能有一批照片的檔案, 然後我在國外隨便路上搭訕了一個正咩拍了他張照片 結果想要猜測他是那一人種!! 最簡單的方式就是開始拿照片比對, 看有沒有跟她長很像的照片, 或者同樣有類似的特徵 我就會猜測她可能是哪種人種 而且如類似照片多的話, 我可以取前幾個都很類似的人, 看哪種人種最多, 就選那種 細部一點解釋, 我可以擷取出了人臉上的各個特徵, 像是 膚色, 輪廓, 眼睛高度, 鼻子高度, 嘴巴高度, 臉長, 臉寬, 髮色...etc 然後去計算每個特徵的差異, 最後加起來差異最小的前幾名再來投票決定 這樣我們就完成簡單的 K-Nearest Neighbor 演算法了 而較常見的計算差異的方法通常是用距離公式, 也就是 euclidean distance 取幾個人做比較也就是那個 k, k 通常都是20~30上下, 當然要看 data 的數量多寡決定 想要有系統的方式去預估 k 就用 cross validation 吧!! 其實這篇只是要為了之後的內容鋪路 XD 因為 kNN 相對簡單, 所以其實結果通常不容易太好, 可是他卻很適合做一些 data 的 preprocess 像是針對 imbalance data 就有一些特別用途, 這留到之後再說